MJ+(行政事務標準文字)
「MJ+(行政事務標準文字)」
データ活用やDX成功に必要な考え方を、各種キーワードの解説で理解できる用語解説集です。
今回は、デジタルガバメントの取り組みで解決が必要になっているデータの事情について、およびデジタル化に取り組む難しさについて、少し考えてみます。
MJ+(行政事務標準文字)とは
MJ+(行政事務標準文字)とは、デジタル庁が、政府の省庁や地方公共団体のITシステムで共通に利用できるように標準化と整備を進めている文字セットです。
日本の公的機関のITシステムでは、人名に用いられる漢字が非常に多くの種類があることなどから、日本語データを取り扱う際の標準化され統一された文字セットがありませんでした。そこで、公的機関の既存のITシステムで利用されているデータから、共通の文字集合(漢字などの字形などの一覧)を整備し、各システムでバラバラだった文字セットを統一する取り組みが進められています。
MJ+(行政事務標準文字)はどうして必要になったのか
現在、デジタル庁は「日本の公的機関のITシステムを良くする」取り組みを進めています。良く知られたものでは、紙ベースでの事務処理のままになっているものなど「デジタル化されていないものをデジタル化する」取り組み(ハンコを廃止するなど)が進められていますが、同じように「既存のITシステムを、より良いITシステムに改める」取り組みも進められています。
例えば、「クラウドの時代だというのに、日本の公的機関のITシステムでは活用できていない、クラウド化を進めよう」というのが後者の取り組みの一例です。クラウド化以外にも公的機関のITシステムにはやらなければいけないことが多くあり、MJ+(行政事務標準文字)も、「公的機関で漢字を取り扱う共通の基盤が(実は)なかった」という大変な問題を解決すべく進められている取り組みです。
200万文字を超える人名漢字
漢字を取り扱う基盤がない、と言われても何だかよくわからないかもしれません。市役所に行ったら普通に日本語の印刷物が出てきますし、我々は日ごろからパソコンやスマホで普通に日本語を使いこなしていますから、パソコン自体で問題なく日本語が使えているようにも思えます。確かに、日常的な日本語利用ならその通りなのですが、役所のシステムには厄介な問題があります。法的な要請から「人名漢字を正確に取り扱わなければいけない」という難題です。
コンピュータができたのは最近であり、それまでは長年にわたって、公的機関での情報管理も「紙ベース・手書き」で運用が続けられてきました。公的機関の業務をIT化するとは、「手書きのアナログ情報をデジタル化する」取り組みでした。そこで問題になったのは、手書きで書かれてきた人名漢字の字形を尊重してIT化する必要があることでした。
私たちが普段使うパソコンでは、約1万文字の日本語圏の文字が登録されていて、その共通の1万文字を使って他のパソコンやスマホとのやり取りもできる環境があります。1万文字は決して少ない文字数ではないのですが、「人名漢字の字体を正確に取り扱う」ニーズには全く足りていません。
通常の日本語処理能力をそのまま使ったのでは、公的機関が求める人名漢字の処理はできないため、公的機関の各システムは独自にシステムで取り扱える漢字を逐次増やして「人名漢字を処理できる能力」の整備を行ってきました。その結果、公的機関の各種ITシステムに登録されている人名漢字の数を(単純に)足し合わせると、なんと200万字を超える状況にまで至ってしまいました。
あまりにも数が多いことのみならず、同じ人名漢字が重複して登録されている、さらには各システムでバラバラに文字登録されている、など問題だらけの状態となってしまいました。MJ+(およびその前のMJ)はこれを「何とか、行政機関のシステムで統一した文字集合にできないか」として進められている取り組みです。
「漢字をコンピュータで取り扱えるようにする」歴史
さて、各システムで取り扱える漢字を逐次増やしたと書きましたが、我々がスマホで「この漢字を増やしたい」とか思ってもそんなことはできませんよね。どうやって増やしたのでしょうか。あるいは、このような混乱を避けるために、どうして最初から全て漢字を共通化していなかったのか?とか思うかもしれません。
このあたりは、コンピュータで漢字を取り扱えるようにしてきた、これまでの経緯を踏まえると、いろいろ事情があって仕方がなかったことが理解できます。そして昨今、デジタル化の取り組みを進めるべきだと盛んに言われますが、「デジタル化されていないものをデジタルにする取り組み一般」での苦労の例としても考えるところもある話かもしれません。
最初期の「コンピュータでの文字」
文字は紙に書いた図形で、一方でコンピュータが処理できるのは本質的に数値だけです。今我々がパソコンで不便なく日本語が使えるのは、数値しか処理できない環境で日本語を取り扱えるようにする環境の整備が、数多くの大変な努力により続けられてきたからです。
コンピュータで文字を取り扱えるようにするためには、自由に描くことができる「紙に書いた図形」を整理して一覧にする必要があります。その図形(字形)をコンピュータ上の数値とどのように結びつけるか(符号化)を整備し、さらにはそのルールで文字列処理をする各種の周辺ソフトウェアも整備する必要があります。
さらには、初期のコンピュータは大変に非力で、取り扱えるデータ量も処理能力も大変限られており、そのようなハードウェア能力の現実的制限を踏まえていなければ実用性もありませんでした。
コンピュータ最初期のそのような例、「アスキーコード」は例えば以下のようなものです。
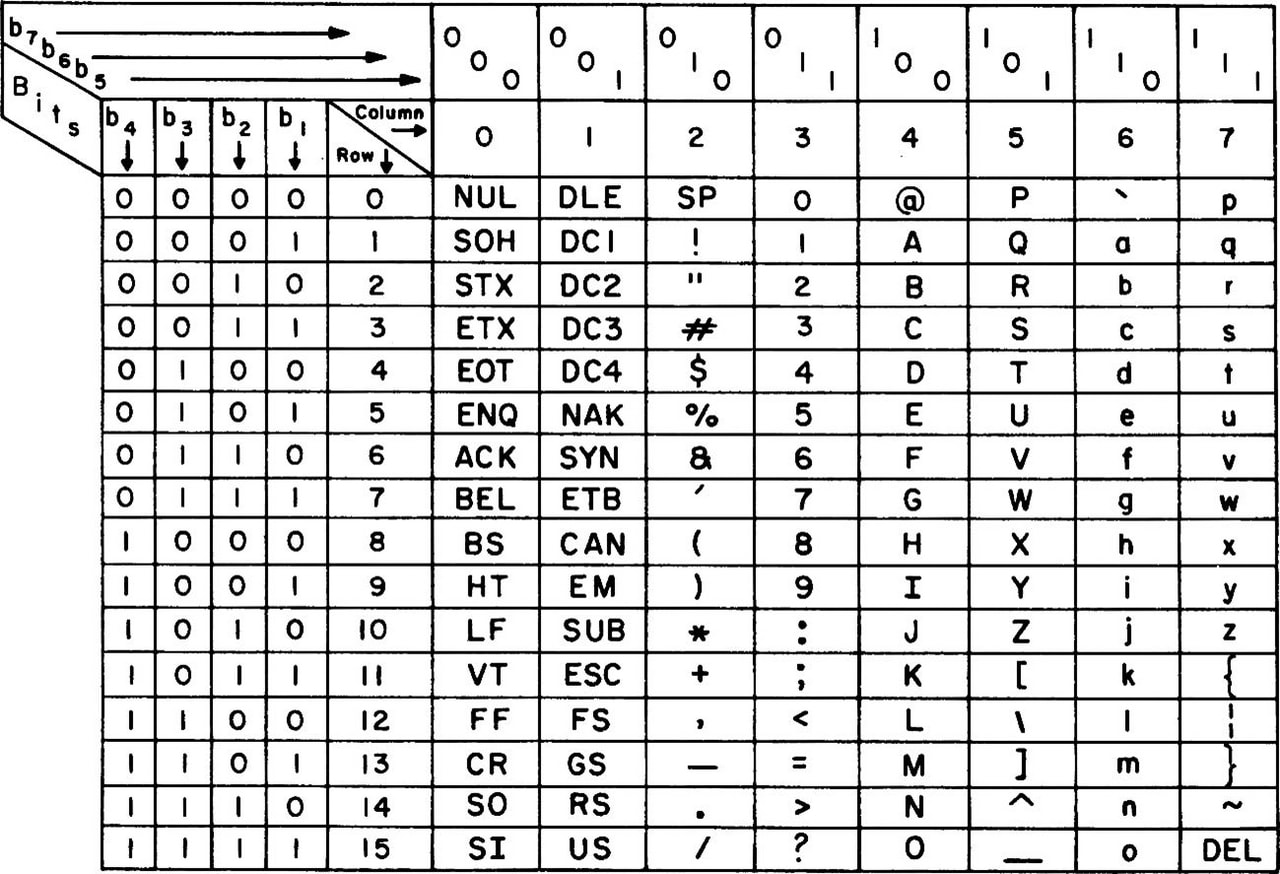
まだコンピュータが非常に高価な時代だったので、一ビット単位でのデータ量の節約が必要であり、一文字7bitに節約して128種類の文字に整理されています。また、最初の32文字は文字表示用ではなく画面制御用のコントロールコードです。
作った人の意図があり、用途にも文字が不足していると使えない
アスキーコードが作られたのは1960年代と、はるか昔ですが「現在でも見慣れた記号文字」があります。アスキーコードは現在利用されている文字コードの基礎になっているため、ここで「選ばれた文字」は今でも使われているためです。例えば、「@(アットマーク)」を我々が今使うのは、アスキーコードにこの文字が入っていたことが大きな原因であろうと思います。
一方で、アスキーコードは英語圏の人の事情に合わせて文字が選んであり、それ以外の事情の人には文字が不足して不便でもあります。例えば欧州の他の国にとってはアットマークなどの記号文字よりも、例えばフランス語やドイツ語で見かける記号付きアルファベット(ÄとかßとかÇとか)、スペイン語の逆さまのはてな記号(¿)の方が必要かもしれません。さらには、日本人にとっては日本固有の文字は全くありません。
一文字で8bitを使うようにすれば256文字まで利用できるようになるので、増えた128文字の部分に各国の事情で必要な文字がそれぞれ足され利用されることになります。128文字もあれば欧州各国の人の不便はひとまずは解決できるようになり、日本においてもカタカナ(環境によってはカタカナ+ひらがな)だけなら表示可能になりました。
パソコンで漢字が使えるようになる(第一水準漢字)
コンピュータの能力向上に伴って、「漢字を処理し表示できるようにする」取り組みが始まります。アスキーコードは文字が選ばれて作られたように、「表示する漢字の一覧」を選んで決める必要があります。なおかつ当時のコンピュータの処理能力は限られていたので文字数は極力抑制する必要があり、少ない文字数で効果的に実用性を高くする必要もありました。
そこで日本で識者が集まり、日本人が良く利用する漢字を調べて、日本産業規格(JIS)によって標準化作業が行われました。これにより定められた、2,965字の「JIS第1水準漢字」への対応がまず進みます。例えば、1980年代に日本で広く使われた8ビットパソコンである「PC-8801シリーズ」では第1水準漢字への対応がなされていました。
第1水準漢字を実際に利用した感覚はどんなものかというと、使いたいと思った漢字が残念ながら表示できずに表現を変えたりする必要は時々はあるが、日本語で文章を打つにあたっては基本的に大きな支障はない、くらいの感じだったと記憶しています。つまり、良く検討されて絞り込まれた2,965字であり、すでにかなりしっかりと「コンピュータ上で日本語を書く」ことができました。カタカナしか使えなかった状況からすると、ものすごい進歩でした。
その後長い間使われる漢字の環境(第二水準漢字+Shift-JIS)
パソコンが16bit時代になり、JIS第一水準と同時に標準化された「JIS第二水準漢字」まで対応した環境が広く使われるようになります。第一水準の2,965字に加えて、新たに3,390字が利用できる環境が普及します。
16bit時代に日本で広く使われたパソコンであるPC-9801シリーズは「JIS第二水準漢字」に対応しており、2バイトのデータでうまく半角文字と全角漢字を混ぜてデータとして記録することができる「Shift-JIS」との組み合わせの環境が日本で広く普及するようになります。
第二水準漢字+Shift-JISは携帯電話のiModeでも採用され、その後、Windowsの時代になっても引き続き広く使われ、今現在でもなおShift-JISの日本語データは目にするのではないかと思います。
ただし人名では入力できないことが時々あった
第二水準漢字では、日本語の一般的な利用において使いたい漢字が無いなどの支障のあることは少なくなりました(だからこそ、長期間使われ続けてきました)。
しかし、人名漢字では「必要な漢字がない」ことは時折起こりました。有名なところでは、元SMAPの「草彅剛」さんの名前が第二水準では打てないため、「草なぎ剛」と表記せざるを得ませんでした。当時のケータイでは名前を漢字で打てなかったので覚えている人もいるでしょう。なお、草彅は秋田などで比較的見られる人名であるため、本来は第二水準に含まれているべき漢字が選定作業時のミスで漏れてしまったと考えられています。
他にも、いわゆるはしご高の「髙﨑」や横棒の上下の長さが通常違う「?田」も含まれていないため、普通の「高崎」や「吉田」として入力されていました。あるいは、パソコンだから人名漢字はしょうがないよね、というような感覚だったと思います。
「外字」
特に16bit時代当時、「必要な漢字がない」時に行われていた作業がありました、「外字登録」です。例えば、取引先にはしご高の「髙﨑」さんが居て、失礼の無いように正しい文字で出力表示したいと思った場合には、「自分でシステムに漢字を追加する」ことが行われていました。
- 「髙﨑」と打ちたいのに「高崎」としか出ない
- じゃあ「外字登録」しよう
- 「髙」を「外字」として自分でパソコンに追加する
つまり自分のマシン環境に「オレオレ漢字」として追加したものが「外字」でした。ちなみにPC-98において漢字フォントとは「16ドット×16ドットでドットを打っただけのもの」だったので、外字登録画面からドットを打つだけで登録はできてしまいました。
ただしこんな対応では「自分のマシン環境限定の文字」に過ぎず、いわば「オレオレ文字」を作っただけなので、それを使ったテキストデータも「オレオレデータ」になってしまいます。
今の感覚なら絶句するような対応です。しかし、当時はネットもない時代、処理は自分のパソコンで完結していることが多く、自分のマシン環境で表示出来て印刷できれば(相手にも印刷して紙で提出するだけなのが当時は通例)現実的に支障がなかったことが多かったのです。なので、漢字が足りないなら「外字として登録する」ことで一応なんとかできている感じになっていました。
「iModeの絵文字」も外字領域
余談ですが、今や世界に定着した絵文字の元祖である「iModeの絵文字」も、一種の外字として実装されていました。Shift-JISの(本来は私的領域の)外字領域の末尾をドコモが占拠して絵文字領域として使って実現されていました。つまり、通信キャリアレベルでのオレオレ文字でした。なので、パソコンでもiModeの絵文字の位置に同じ形の外字を登録すれば、ドコモの絵文字が使えたりしました(文字に色はつきませんでしたが)。
再度、公的機関での漢字の問題
このような「第二水準漢字+Shift-JIS(+外字)」でのテキストデータ利用は1990年代に始まり、Unicodeが主流になってくる2010年代後半までは主流だったと思います。
Windows時代になっていた2000年に、「JIS第三水準漢字(1,259字)」「JIS第四水準漢字(2,436字)」が追加され、漢字以外の文字もあわせて1万字を超える漢字が標準化されました。この追加により、「良く知られた入力できない人名漢字」もおおむね追加された印象で、例えば「草彅」や「髙﨑」「?田」も打てるようになりました。さらには、Unicodeの普及が進んだことで、これら多くの文字を実際に活用する環境も整い始めます。それが「現在われわれが使っている環境」(JIS X 0213:2004)です。
「文字が足りない」なら、「外字登録」が行われてきた
ただし、1万字であらゆる人名漢字を網羅できたかというとそんなことはありませんでした。そこで、パソコンで漢字がないときに「外字登録」がなされていたことと同じような対応が、公的機関のITシステムでも取られてきました(パソコンとはIT環境は違ったりしましたが、根本的に文字が足りないのは同じでした)。
つまり紙の書類から入力をするときに、標準の文字に無い人名漢字を入力する必要が生じると、「外字登録」をして対処するような対応が続けられてきました。そのようにして多数の人名漢字が追加されて利用されることになりました。さらには、各システムでバラバラに外字が登録されることで、それぞれの環境でしか処理できない「オレオレ文字」が登録されている状態になってしまいます。
デジタル庁が整理しようとしている「200万文字」とは、このようにしてあちこちのシステムに登録されて増えていった「外字」の総数です。
2011年の取り組み、MJ(文字情報基盤)
そのような状況では、システム間でのデータ移動すらスムーズにできないなど多々非効率であるため、文字を共通化して問題を解決すべく取り組みがすでに一度進められました。具体的には、人名漢字を正しく取り扱う必要のあるシステム(つまり問題の主たる発生源の)である、「戸籍に関するITシステム」と「住民基本台帳のITシステム」で利用されていた文字を整理して、共通化する取り組みが行われました。
2011年に、すでに標準化されていた「JIS第一水準漢字から第四水準漢字までの文字」に加え、「戸籍システムの文字」を整理したもの、「住民基本台帳ネットワークの文字」を整理したものを加えた、約6万字の「MJ(文字情報基盤)」が作られます。
整備された文字はUnicode上で利用できるようになり、画面表示するためのフォント(IPAmj明朝フォント)も整備され、フォントをインストールすれば一般のパソコンでもMJ文字の六万字が表示できるようになりました。
画期的な取り組みでしたが、残念なことにそれから時間が経った現在、現実問題としてMJ文字だけで済むようにはなっていません。戸籍システムや住基ネットですら外字が利用され登録され続ける状況が続いています。
MJ+(行政事務標準文字)
2021年に発足したデジタル庁により、今度こそ混乱を収拾しようと再度進められているのが「MJ+(行政事務標準文字)」です。MJ文字をベースにして再度足りない文字を確認・整理して追加し「共通の文字集合」を整備することを目指しています。
ひとまず、MJ文字にさらに約1万字が追加されて全体で約7万字となり、フォントの整備も行われましたが、依然として難しい状況があり、これで万事解決した感じにはどうやらなっていないようではあります。
- 一つのフォントファイルで運用できない:
文字数が多すぎるため、一つのフォントファイルにすべての文字を格納できなくなっています。フォントファイルの中でも多数の文字を取り扱うことができるOpenTypeでも約6万が上限であるため。そのため、複数のフォントファイルに分割する必要が生じています。 - 漢字ごとにフォントファイルを切り替える処理が必要に:
複数のフォントファイルが必要になるということは、パソコン上では別のフォント扱いということです。「表示する漢字ごとに表示フォントを切り替える処理が必要になる」ということです。一般のアプリケーションからするとあり得ない動作であるため、MJ+のために改修したソフトウェア以外では利用が難しくなりました。 - 外字を無くせるかどうかがまだ怪しい:
MJ文字では外字を廃止できなかったことを踏まえて、今度こそ外字を無くすことを目標としているわけですが、今度こそ外字が無くすことができ、今度こそ文字追加をしなくてよくなったのかどうか、まだ予断を許さない状況のようです。つまり、外字利用を解消できなかったり、MJ+にさらなる追加変更がなされる可能性は排除できないようです。
そもそも、大量の文字を利用する必要があるのかどうか
またそもそも、このような取り組みの前提となっている「大量の漢字」が本当に必要なものなのかも、考えなければいけないポイントでしょう。
例えば、渡辺の「辺」のバリエーションが100種類以上登録されているようなのですが、本当にそんなに多くのバリエーションが必要なのかは議論のあるところではないかと思います。登録されている字形には、書き間違いなどで生まれた無意味なバリエーションもあるはずです。「渡辺」の一種類にすべて統一だ、というのは乱暴すぎるにしても、普通のパソコンの一万文字でも既に「渡辺」「渡邊」「渡邉」などは簡単に打てる状況にはなっています。
すでに「一つのフォントファイルに入らない」事態に陥っており、MJ+を一般のITシステムで利用することは困難になって、実用性が危ぶまれる状態となっています。アプリケーションすら専用に対応したものが必要になるような、利用するだけで多大なコストをかかる状況になってもなお、人名漢字のすべてのバリエーションを保持する必要があるのかは国民で議論すべきことのようにも思えます。
例えば、政府が公共機関で利用する標準漢字を整備し(例えば「JIS第四水準漢字」まで、あるいは「MJ文字」まで)、公共機関のITシステムではそれ以外の漢字の利用を禁止します、としてしまえば問題は一気に解消します。
ただし、文字の喪失は元に戻せない文化の喪失ではある
ただし、手書きで受け継がれてきた「文字の形」は日本文化の一部でもあります。行政機関が思い切った「標準化」をしてしまうと、人名漢字の多様性はここで絶たれて未来に引き継がれなくなります。また、自身の人名漢字の独自性にアイデンティティーを感じている人々も存在します、その人たちにとっては個人の権利や尊厳の問題になりえます。
あるいは「漢字は整理して減らしてしまえばよい」という考え方をさらに進めると、日本以外(中国や台湾など)の漢字との重複が無駄だから統一しなさいみたいな話にもなりえます。現実にスマホアプリでも、日本語で利用しているのに中国語的なフォントで漢字が出てしまうアプリが見られます。そういうアプリを使ったときに「これはちょっと」と思ってしまうことはないでしょうか、もしそうなら我々も「固有の漢字の形」にアイデンティティーを感じているということになります。
だからといって、外字200万文字の全て(あるいはMJ+の7万字の全て)がそのまま残すべきものなのかは別の話のはずです。そういうことも踏まえた上で、日本の漢字をどのように残してゆくのかを考える必要があります。
あるいはこの問題は、技術的な正解がある問題ではなく、「漢字を将来にどのように残すべきかについて、どのように考えるか」の問題であり、様々な結論があり得る問題ということになります。
データ入力やデータ連携など技術的問題も生じる
ここまで話題にしてきたような「どの文字を選んで残すか」の問題以外にも、ITシステムで多くの人名漢字を取り扱えるようにするために、取り組まなければならないことがあります。
単に文字数を増やす以上の対応が必要
例えば「渡辺」には、「渡邊」「渡邉」などの100以上のバリエーションが存在しますが、これらを単に違う漢字としてバラバラに登録するのではなく、同じ「辺」のバリエーションとして登録する必要があります。それぞれバラバラの字になってしまうと、例えば苗字が「わたなべ」の人を漢字で検索することが難しくなったりします。
技術的にはすでにUnicodeに「同じ漢字だが字の形にバリエーションがある」場合に表示を切り替えられる機能があり(異体字セレクタ、あるいはIVS:漢字異体字シーケンス)、一部アプリケーションでもこの機能が実装されて利用できます。
つまり技術的な基盤はありますが、どの漢字をどのようなバリエーションとして登録するのかは人が整理する必要があります。もしかすると関連する漢字がはっきりしない人名漢字や、一意に特定できないようなケースもあるかもしれません。
多数の漢字から文字を探す機能(専用UIなど)が必要になる
同じ漢字に大量のバリエーションがありうる状態でも、データの入力作業など、データに関するオペレーションが現実的に行えるシステム環境を整備する必要もあります。
例えば、我々が普段使っている漢字変換機能をそのまま流用したら「わたなべ」と入力したら100種類以上も候補が出てくるような状況になってしまい、ちょっと現実的に利用できないはずです。大量の人名漢字があっても問題なく必要な漢字を選べるように、しかも字の形がわずかに違うだけの人名漢字が大量にある中から、意図した字形の文字を効率的に選び出せるUIの整備などが必要になります。データ入力以外の処理(検索など)でも、同じように配慮が必要になることがあるはずです。
外部システムとのデータ連携
さらには、「外部システムとのデータ連携をどうするのか」も大きな問題になります。
これからは、公的機関のサービスもデジタルサービスとして利用する時代になってゆくはずですから、さまざまな形での「外部のシステムとのデータ連携処理」の実現が避けられません。昔とは違って「紙に印刷して渡すからデジタルデータで連携できなくても問題はない」というわけにはいきません。
しかも今後、日本のITシステムの大半がMJ+を利用できる環境となるとは考えにくい状況です。公的機関のシステムでは対応が進んだとしても、民間の多くのITシステムや、あるいは多くの一般の人が使うパソコンやスマホでも対応が進むとは考えにくい状況ですから、日本全体では対応していない環境が広く使われ続けることが予想されます。
MJ+を利用できない外部システムにデータをそのまま送信すると、意図した通りに漢字が表示できなくなってしまう可能性があります。データ連携に際して、MJ+に対応していない環境の個別事情に配慮する必要があります。さらには、日本では何十年も昔から稼働しているシステムもまだまだ使われていますから、一般のパソコンやスマホとも異なる環境(メインフレームなど)とのデータ連携が求められることも出てきます。
つまりMJ+を利用している環と、外部の多種多様な環境の間を、適切なデータ変換とデータ受け渡しを行えるようデータ連携処理を整備する必要があります。
公的機関のITシステム自体でのデータ連携の問題
このような「データ連携の問題」は、公的機関のITシステム同士でも発生します。MJ+ができたからといって、その日を境に全てのITシステムや既存データが対応済みになるわけではないからです。
まだ未対応のシステム、部分的に対応したシステムなどが当面の間は混在するはずです。データについても、未対応のデータや、移行中で部分的に対応しているデータが混在する状況が続くはずです。同じく、相手の環境に合わせたデータ連携の整備が必要になります。
MJ+への対応作業自体もデータ連携の問題
さらには、MJ+対応を進める作業そのものについても、旧環境にあるデータを変換してMJ+に対応させたデータに変換する処理ですから、同じようにデータ連携の問題だと言えます。
すでに話題にしたように、今度こそMJ+で人名漢字の問題がきちんと片付くのかはっきりしない印象もあります。もし今後、MJ+に新たな変更が行われた場合には「MJ+のどのバージョンに対応しているITシステム(あるいはデータ)か」を踏まえて、対応状況にあわせたデータ連携処理が必要になることも考えられます。
人名漢字の問題以外にも、データ連携を活躍させるために取り組むべきことがある
今後世の中でIT活用を深化させるためには、ITシステムにまたがってのデータ活用を実現する必要があり、そのためデータ連携は今後ますます重要になります。MJ+は、人名漢字を含むデータを、ITシステムにまたがってデータ連携する場合の大きな障害を解決する取り組みともみなせます。
あるいは言い換えるなら、ここまで話題にしてきたような「人名漢字の問題」は、データ連携における一つの問題にすぎません。それ以外にもITシステムには環境や事情の違いがあり、それらを踏まえてスムーズにシステム同士が連携できる環境を整備する必要があります。
いつの間にか複雑怪奇になりやすいデータ連携
データ連携は、必要に応じて個別に開発され始めることが多いのですが、IT活用が進むにつれて連携処理がいつの間にか増えてしまい、気が付いたら収拾がつかないくらいの多数の連携処理が稼働している状態になっていることがあります。つまり、データ連携を作ること自体が、データ連携の維持を難しくしてしまうことがあります。
また、広範に外部システムとのデータ連携に取り組むと、事前にそれぞれのITシステムや事業分野の事情を十分に理解した状況で整然とデータ連携を開発できる状況だけではなくなってきます。実際に連携させてみてから、吸収しなければいけないデータ形式やデータの考え方の違いがあることに気が付くこともありますし、ビジネスでの新しい取り組みに伴ってデータ連携にも変更が必要になることもあり、素早く柔軟に連携処理を作り直せることも望まれます。
そして、多数の連携処理が作られ、それぞれ個別に改修が続けられると、全体としてどことどこがどのように連携しているのかよくわからなくなってしまうこともあります。つまり、データ連携処理をよりよく作りこみ続けることが必要な一方で、作りこみがデータ連携全体を理解困難にしてしまうことがあります。
データ連携基盤の整備が必要になる
いわば、人名漢字を利用できるようにしようと利用環境を整備する努力が個別に続けられた結果、MJ+の整備が必要になってしまったのと同じ種類の問題です。人名漢字に共通プラットフォームが必要になったように、データ連携を全体としてうまく整備できるようにする「データ連携基盤」が必要になることがあります。
MJ+により共通の文字基盤が整備できなければ公的機関でのIT活用に支障があるように、データ連携がうまく実現できなければIT活用をうまく進めることができなくなったりします。では、データ連携基盤とはどのように実現すればよいのでしょうか。もしかしたら、技術力などが必要で自分たちには難しい話に思えてしまうかもしれません。
データ連携を現実的かつ効果的に実現する「つなぐ」技術
しかし、そのようなデータ連携のニーズを「GUIだけ」で効率的に開発し実現できる手段が存在します。「EAI」や「ETL」、「iPaaS」と呼ばれる、「DataSpider」や「HULFT Square」「DataMagic」などの「つなぐ」技術です。これらを活用することで、データの自動連携処理をスムーズかつ効率的に実現することができます。
GUIだけで利用できる
通常のプログラミングのようにコードを書く必要がありません。GUI上でアイコンを配置し設定をすることで、多種多様なシステムやデータ、クラウドサービスへの連携処理を実現できます。
「GUIで開発できる」ことは長所でもある
GUIだけでのノーコード開発は、本格的なプログラミングに対して簡易で妥協的な印象を受けるかもしれません。しかしながら、GUIだけで開発できることは「業務の現場の担当者が自分たち自身で主体的にクラウド連携に取り組む」ことを可能にします。
ビジネスのことを一番良くわかっているのは現場の担当者です。彼ら自身によって、データ連携にあたってどういう配慮をしたデータ変換が必要になるかを踏まえて、必要なことをどんどん作りこめるのなら、何かあるたびにエンジニアに説明してお願いしないと開発できない状況より、優れているところがあるはずです。
本格的処理を実装できる
「GUIだけで開発できる」ことを謳っている製品は沢山ありますが、そういう製品に簡易で悪い印象を持っている人もおられるかもしれません。
確かに、「簡単に作れるが簡易なことしかできない」「本格的処理を実行しようとしたら処理できずに落ちてしまった」「業務を支えられるだけの高い信頼性や安定稼働能力がなくて大変なことになってしまった」ようなことは起こりがちです。
「DataSpider」や「HULFT Square」は、簡単に使うこともできますが本格的プログラミングと同等のレベルの処理の作りこみもできます。内部的にJavaに変換されて実行されるなど本格的プログラミングと同様の高い処理能力があり、長年にわたって企業ITを支えてきた実績もあります。「GUIだけ」の良さと、プロフェッショナルユースとしての実績と本格的能力の両方を兼ね備えています。
データ活用を成功させる「データ基盤」として必要なこと
多種多様なデータソースへの接続能力はもちろん必要になりますし、大量のデータを処理することになることがあるために高い処理能力、その一方で、データ活用では試行錯誤がどうしても重要になることが多く、現場主導でデータ連携を柔軟かつ迅速に作り、あるいは作り直せることも必要になります。
一般的には、高い性能や高度な処理の実現を求めると本格的なプログラミングや利用が難しいツールとなりがちで、現場での使いやすさを求めると利用しやすいが処理能力が低く簡易な処理しかできないツールになりがちで、このようなジレンマ、あるいはどちらかを我慢するトレードオフだと思われてしまっていることもあるかと思います。
さらに加えて多種多様なデータソース、特にメインフレームなど昔からあるITシステムや現場のExcelなどモダンではないデータソースへの高度なアクセス能力と、クラウドなど最新のITへのアクセス能力も併せて持っている必要があります。
この条件のいずれかを満たすだけなら多くの手段があるでしょうが、データ活用をうまく進めるためにはすべての条件を満たす必要があります。しかし、現場でも十分に使えるが、プロフェッショナルツールとして高い性能や信頼性を兼ね備えている、そんなデータ連携の実現手段となると多くはありません。
iPaaSなので自社運用不要
DataSpiderなら自社管理下のシステムでしっかりと運用できます。クラウドサービス(iPaaS)のHULFT Squareなら、このような「つなぐ」技術そのもの自体もクラウドサービスとして自社運用不要で利用でき、自社での導入やシステム運用の手間がなく利用できます。
関係するキーワード(さらに理解するために)
- EAI
- システム間をデータ連携して「つなぐ」考え方で、様々なデータやシステムを自在につなぐ手段です。IT利活用をうまく進める考え方として、クラウド時代になるずっと前から、活躍してきた考え方です。
- ETL
- 昨今盛んに取り組まれているデータ活用の取り組みでは、データの分析作業そのものではなく、オンプレミスからクラウドまで、あちこちに散在するデータを集めてくる作業や前処理が実作業の大半を占めます。そのような処理を効率的に実現する手段です。
- iPaaS
- 様々なクラウドを外部のシステムやデータと、GUI上での操作だけで「つなぐ」クラウドサービスのことをiPaaSと呼びます。
DataSpiderの評価版・無料ハンズオン
当社で開発販売しているデータ連携ツール「DataSpider」は、ETLとしての機能も備えており、多数の利用実績もあるデータ連携ツールです。
通常のプログラミングのようにコードを書くこと無くGUIだけ(ノーコード)で開発でき、「高い開発生産性」「業務の基盤(プロフェッショナルユース)を担えるだけの本格的な性能」「業務の現場が自分で使える使いやすさ(プログラマではなくても十分に使える)」を備えています。
データ活用のみならず、クラウド活用などの様々なIT利活用の成功を妨げている「バラバラになったシステムやデータをつなぐ」問題をスムーズに解決することができます。
無料体験版や、無償で実際使ってみることができるハンズオンも定期開催しておりますので、ぜひ一度お試しいただけますと幸いです。
用語集 コラム一覧
英数字・記号
- 2025年の崖
- 5G
- AI
- API【詳細版】
- API基盤・APIマネジメント【詳細版】
- BCP
- BI
- BPR
- CCPA(カリフォルニア州消費者プライバシー法)【詳細版】
- Chain-of-Thoughtプロンプティング【詳細版】
- ChatGPT(Chat Generative Pre-trained Transformer)【詳細版】
- CRM
- CX
- D2C
- DBaaS
- DevOps
- DWH【詳細版】
- DX認定
- DX銘柄
- DXレポート
- EAI【詳細版】
- EDI
- EDINET【詳細版】
- ERP
- ETL【詳細版】
- Excel連携【詳細版】
- Few-shotプロンプティング / Few-shot Learning【詳細版】
- FIPS140【詳細版】
- FTP
- GDPR(EU一般データ保護規則)【詳細版】
- Generated Knowledgeプロンプティング(知識生成プロンプティング)【詳細版】
- GIGAスクール構想
- GUI
- IaaS【詳細版】
- IoT
- iPaaS【詳細版】
- MaaS
- MDM
- MFT(Managed File Transfer)【詳細版】
- MJ+(行政事務標準文字)【詳細版】
- NFT
- NoSQL【詳細版】
- OCR
- PaaS【詳細版】
- PCI DSS【詳細版】
- PoC
- REST API(Representational State Transfer API)【詳細版】
- RFID
- RPA
- SaaS(Software as a Service)【詳細版】
- SaaS連携【詳細版】
- SDGs
- Self-translateプロンプティング /「英語で考えてから日本語で答えてください」【詳細版】
- SFA
- SOC(System and Organization Controls)【詳細版】
- Society 5.0
- STEM教育
- The Flipped Interaction Pattern(解らないことがあったら聞いてください)【詳細版】
- UI
- UX
- VUCA
- Web3
- XaaS(SaaS、PaaS、IaaSなど)【詳細版】
- XML
- ZStandard(可逆データ圧縮アルゴリズム)【詳細版】
あ行
か行
- カーボンニュートラル
- 仮想化
- ガバメントクラウド【詳細版】
- 可用性
- 完全性
- 機械学習【詳細版】
- 基幹システム
- 機密性
- キャッシュレス決済
- 共通鍵暗号 / DES / AES(Advanced Encryption Standard)【詳細版】
- 業務自動化
- クラウド
- クラウド移行
- クラウドネイティブ【詳細版】
- クラウドファースト
- クラウド連携【詳細版】
- 検索拡張生成(RAG:Retrieval Augmented Generation)【詳細版】
- コンテキスト内学習(ICL: In-Context Learning)【詳細版】
- コンテナ【詳細版】
- コンテナオーケストレーション【詳細版】
さ行
- サーバレス(FaaS)【詳細版】
- サイロ化【詳細版】
- サブスクリプション
- サプライチェーンマネジメント
- シンギュラリティ
- シングルサインオン(SSO:Single Sign On)【詳細版】
- スケーラブル(スケールアップ/スケールダウン)【詳細版】
- スケールアウト
- スケールイン
- スマートシティ
- スマートファクトリー
- スモールスタート(small start)【詳細版】
- 生成AI(Generative AI)【詳細版】
- セルフサービスBI(ITのセルフサービス化)【詳細版】
- 疎結合【詳細版】
た行
- 大規模言語モデル(LLM:Large Language Model)【詳細版】
- ディープラーニング
- データ移行
- データカタログ
- データ活用
- データガバナンス
- データ管理
- データサイエンティスト
- データドリブン
- データ分析
- データベース
- データマート
- データマイニング
- データモデリング
- データリネージ
- データレイク【詳細版】
- データ連携 / データ連携基盤【詳細版】
- デジタイゼーション
- デジタライゼーション
- デジタルツイン
- デジタルディスラプション
- デジタルトランスフォーメーション
- デッドロック/ deadlock【詳細版】
- テレワーク
- 転移学習(transfer learning)【詳細版】
- 電子決済
- 電子署名【詳細版】
な行
は行
- ハイブリッドクラウド
- バッチ処理
- 非構造化データ
- ビッグデータ
- ファイル連携【詳細版】
- ファインチューニング【詳細版】
- プライベートクラウド
- ブロックチェーン
- プロンプトテンプレート【詳細版】
- ベクトル化 / エンベディング(Embedding)【詳細版】
- ベクトルデータベース(Vector database)【詳細版】
ま行
や行
ら行
- リープフロッグ現象(leapfrogging)【詳細版】
- 量子コンピュータ
- ルート最適化ソリューション
- レガシーシステム / レガシー連携【詳細版】
- ローコード開発(Low-code development)【詳細版】
- ロールプレイプロンプティング / Role-Play Prompting【詳細版】