
株式会社セゾン情報システムズ(現セゾンテクノロジー)は、「データの民主化」の実現、すなわち全社員が自らの意思で自発的にデータを利活用して業務を改善できるようにする、という目標を掲げ、全社データドリブンプロジェクトを発足。「データを集め、溜め、探し、活かす」ためのすべての機能を搭載した基盤「データドリブンプラットフォーム」(以下、DDP)を構築した。同プロジェクトの推進役を務めたコーポレートデベロップメントセンター ITサポート部の佐々木勝氏に、プロジェクトの立ち上げから企画、構築、活用、定着までに行ったことや注意点、DDP活用の成果などについて話を伺った。
“ひらめき”や“仮説”を誰でも検証できる「データの民主化」を目指し、DDPの構築に挑む!
はじめに、今回構築したDDPとはどういうものか、簡単に説明してください。
ひと言でいうとデータウェアハウス(DWH)に活用ツールをドッキングさせた仕組みで、「データを集め、溜め、探し、活かす」ためのすべての機能を搭載した基盤です。社内のユーザーは、検索・抽出しやすい状態で全社に公開されているDWHのデータを参照して、目的に合わせて自らデータマートを作成し、データを利活用できます。
データを「集める」「溜める」のはもとより、その先にある「探す」「活かす」というゴールを達成するために必要なものとして、弊社では「4種の神器」を定めました。欲しいデータがどこにあるかを探せるデータカタログ、データを結合・加工するDWH、データ抽出の処理を自動化するデータ連携ツール、分析・可視化するBIツール。ユーザーは、目的やリテラシーに応じて、これら4つを組み合わせて利用します。
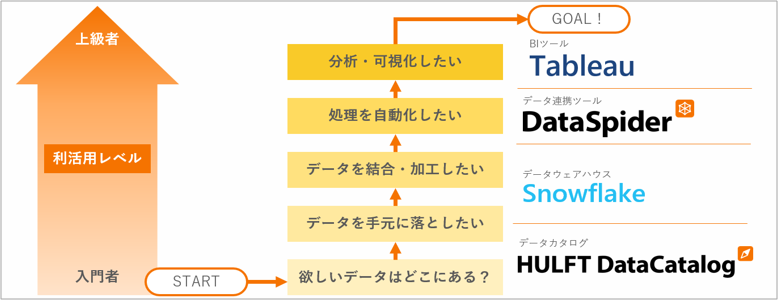
セゾン情報システムズ(現セゾンテクノロジー)のDDPを構成する「4種の神器」。以下の4つのツールからなる
- 利用者が必要なデータを探し出し、データの意味を理解するデータカタログ
- データを検索・抽出しやすいよう整理して溜めておくデータウェアハウス
- データの抽出・加工を自動化するデータ連携ツール
- データを様々な切り口で分析・可視化するBIツール
では、そのDDPの構築プロジェクトをどのように進めたのか、順を追って解説してください。
最初にもっとも重要である、「なぜ今データドリブンが必要なのか?」という課題背景を明確にすることから始めました。まずは経営・営業面にとってのメリット。弊社は「データエンジニアリングカンパニー」を標榜し、データを俊敏にビジネスの意思決定につなげるサービスをお客様に提供しています。そうしたビジネスを進める上では、実際にデータを利活用して企業競争力を向上させるという、自らの体験をもってお客様に価値を届けることが大切ですから、その意味で今回の取り組みは重要な意味を持つといえます。
一方、社内のユーザーにとっても大きなメリットがあります。従来弊社では、各社員がそれぞれの担当業務の品質向上や効率化を目的としてデータを利活用したいと思っても、簡単には実行できませんでした。というのもユーザーは、目的に適うデータが社内に存在しているかを自分で調べ、データオーナーに使用目的を伝えてデータの提供を受け、データが表しているビジネス上の意味を確認し、分析・自動化を作り込むという、非常に煩雑な作業をしなければならなかったからです。今回の取り組みによってユーザーは、データ利活用の手順やノウハウを身につけ、あらかじめ使える状態に整理されたデータを手軽に参照し、分析・自動化のツールを自由に使って目的を達成できるようになります。
同時に、私たち情シスの長年の悩みも一気に解消されます。これまでは、データを使って可視化・分析強化したいというニーズが社内に非常に多く存在するのに、情シスのリソース不足によって対応が追いつきませんでした。また、情シスは各業務の専門家ではないので、依頼ごとに求められる分析軸を理解するのに苦労していました。さらに、依頼ごとに構築して400以上に膨れ上がった作業用データベースの管理が非常に大変でした。そうした課題をDDPですべて解決できるのです。
まずそのようにプロジェクトの目的をはっきりさせるのが大切ということですね。
そうですね。加えてもう1つ、実現すべき姿を明確化することも重要だと思います。その点について弊社では「データの民主化」、つまり日々の業務の中で生まれる“ひらめき”や“仮説”を誰でも検証できる状態、と定義しました。そして、それを実現するために、「すべてのデータがこの基盤の中にあると全社員に認知されていること」「データリテラシーのある社員が増え、データに対する影響やリスクを理解できるようになること」など5つのゴールを設定しました。
では、それらのゴールを達成するには、具体的にどういうシステムを作ればいいのか? それを明らかにするために、想定されるユーザー体験をできるだけたくさん挙げ、それぞれについてDDPが備えるべきシステム機能をひとつひとつ定義し、一覧にしました。それを見ながら各機能を実装する優先順位をつけ、アジャイル開発に着手したのです。

プロジェクトの立ち上げにあたっては、どんな観点から参画メンバーを選ぶかも重要ですよね。
その通りです。そこで弊社ではステークホルダー、DDPの利害関係者の人物像を定義して、その中から誰を巻き込むべきかを検討しました。まず絶対に必要だと考えたのが、データと業務の関連性を知り、意味づけのできるデータオーナーです。また、すでにデータを使ってなんらかの業務を行い、課題や痛みを実感しているデータ利用者の参加も不可欠です。エンジニアだけのプロジェクトチームでもデータ基盤を作ることはできますが、それだと「集める」「溜める」が目的化しがちで、その先にある本当のゴールの達成は難しくなります。データの意味や業務の課題を知る人の頭の中にこそ、DDPに求められる“真の要件”があるわけですから、そうしたメンバーには必ず参画してもらわなければならないと考えました。
加えて、主な利用者になると想定される人や、後ほど詳しく話しますが、データの利活用レベルに合わせて分類した6階層のペルソナからも適任な社員を選び、プロジェクトに巻き込んでいくことにしました。
そうしたメンバーの参画が大事だというのはよくわかりました。ただ、実際には日常の業務で忙しく、全員の協力を得るのはなかなか難しいですよね。
そう、確かに部門間の調整というレベルでは、必要な時間を割いてもらえないでしょう。そこで弊社では、経営層から「全社でデータドリブンを進めていくので、指名されたメンバーはミッションとしてプロジェクトに参画するように」という強いメッセージを発信してもらいました。そうすることで、全社に必要性を認識させ、DDPの要件を握る重要人物として私たちの求める人材をアサインできたのです。
そうしてプロジェクトの全メンバーが一堂に会し、キックオフの実施に至りました。メンバーには、4か月間のタスクフォースとしてプロジェクトへの参加を依頼し、改めて背景課題と目指すべきゴールを共有しました。
それから、プロジェクトへの参画によってメンバーと業務部門が享受できる2つの価値についても説明しました。1つは、情シスメンバーによるスキル習得のサポートによって、メンバーはデータ活用リテラシーを高め、業務の生産性向上を自らの手で実現できるようになること。もう1つは、当該部門が有するデータを集約し共有することで、データを使って業務の属人化を解消できることです。要するに、プロジェクトへの取り組みは、結局自分たちのメリットとして返ってきますよ、と伝えることで、モチベーションの向上を図ったわけです。
そのようにしてプロジェクトが始まり、次の企画・構築のフェーズで最初に取り組んだことは?
まずはデータを集める作業です。社内にどんなデータがあるかを洗い出すため、存在するすべてのシステムを列挙し、それぞれの担当者へのヒアリングを実施しました。そのシステムのデータに責任を持つオーナーはどの部門で、共有する価値のあるものなのかをヒアリングを通じて判断し、「使える」「使えない」「使えそう」の3種類にデータを分けていきました。
次に、対象システムのオーナーとエキスパートを確定させました。調べると社内には約160ものテーブルがあることがわかったので、それぞれについてオーナーが誰なのか、そのテーブルの保有データにもっとも精通しているエキスパートは誰なのかを確かめたわけです。そして、そのデータが分析・自動化・可視化に使えそうかをオーナーとエキスパートに確認して、使えそうにないデータについては除外するなど、DWHに格納するデータを選定していきました。
その際に考慮したポイントは、現状ニーズはないものの将来的にデータ分析に使う可能性を見込めるデータは格納対象としたこと。反対に、秘匿性が極めて高く公開がリスクにつながるデータや、顧客との契約上公開すべきでないデータは格納の対象外としたことです。

データドリブンプラットフォームプロジェクトリーダー 佐々木勝
単純に社内のあらゆるデータを集めてDWHに格納すればいい、というわけではないのですね。
そうですね。あと、対象データをどのようなタイミング・方式で収集するかを決める際にも注意が必要です。データの種類には大別して3つ、過去の時点情報が必要なため洗替方式で全データを毎日リフレッシュすべき「マスタ系データ」、日々差分データが発生するため前日発生データを追加すべき「トランザクション系データ」、中間データベースでデータを完成させてから洗替・追加すべき「中間的な性質を持つデータ」があります。それらの特性や想定される用途に合わせて、データを格納するタイミングや抽出要件を明確にしておく必要があります。
データを「集める」作業が一段落したら、次は「溜める」作業ですね。
はい。まずはデータの公開範囲を整理しました。当然ながらデータの中には、マスキングする必要のある秘匿性の高いものもあります。よって、テーブル自体、あるいはテーブル内の各項目をどこまで公開すべきかを慎重に検討しなくてはなりません。
結果として弊社の場合、公開方法を4パターンにモデル化しました。「全社員に全データを公開」「社員に公開するが、一部項目は特定部門以外マスク」「特定部門に所属する社員に限り全データを公開」「特定の社員に限り全データを公開」の4つです。
次にデータの下処理です。いわゆる“汚いデータ”、たとえば人によって表現の異なる項目(揺らぎ)などや、単体では使いものにならないデータなどは、そのままではDWHに格納できません。そういうものがないかをオーナーに確認し、ある場合にはデータ連携ツールを使ってきれいにしたり、そもそもの入力運用から変えたりして対応しました。
だいたいここまでが、データを「集める」「溜める」のに必要とされた作業です。次はいよいよユーザーに直接関わる領域、「探す」「活かす」ための作業に入っていきます。
DDP利用開始から4か月で業務改善効果を実感、社員の意識や働き方もデータドリブンへ前進
データを「集める」「溜める」ことはできましたが、そこまでならできている企業はたくさんありますよね。
そうですね。しかし、「データ入れたよ! はいどうぞ」だけでは、ユーザーはデータを使えません。自力で必要なデータにたどり着く方法を与えられていないからです。企業においてデータ活用がなかなか普及しない要因の1つは、まさにそこにあります。「~がしたい」「~なのでは?」というユーザーの要望やひらめきに対して、「それならこのデータを使えばいいよ」という筋道を示してあげる必要があるわけです。
そのためのツールがデータカタログです。これはひと言でいうと「データ辞書」で、データの所在や説明、件数、来歴、管理者など、データに付随するメタ情報を管理するツールです。データの品揃えや、データの示すビジネス上の意味を“共有知”にすることで、検索で簡単に必要なデータを探せる状態にします。
このメタ情報がいかに洗練されているかが、ユーザーの使い勝手に直結する重要なポイントです。システムの人間が考えてつけるのではなく、実際にそのデータを業務で使っている人たちの用語でつけてもらう必要があります。
検索によって社内の必要なデータにたどり着くという作業は、従来、情シスしか実施できないことでした。データカタログを全社展開することで、社員が主体的にデータを活用できるようになったわけですね。
そうなのですが、そこで問題となるのがセキュリティです。これまでは、データにアクセスできるのは情シスだけだったので、セキュリティの考慮点は限定的でした。しかし、全社員がいつでもデータにアクセスできるDDPの世界では、当然ながらセキュリティの考慮点は増えます。利便性とセキュリティはトレードオフなのです。
そこで弊社では、ロールベースアクセスコントロールという方法を採用しました。全社員に必ず1つ以上のロール(役割)をアサインし、ロールによって「データを見せる/見せない」をコントロールする仕組みです。見せ方としては、テーブルそのものを「見せる/見せない」ということもできますし、テーブルの列単位でコントロールすることもできます。たとえば社員マスタ系のテーブルなら、テーブル自体は全社員に見せるけれども、給与情報や住所情報といった特定の項目は列単位で人事部の社員にしか見せない、などと制御できるわけです。

なるほど。セキュリティを担保しつつ、社員がデータを業務に活かせる状態になったわけですね。
はい。データを「活かす」上では、社員が自らの手で業務改善を行えるように、申請制で社員にツールを提供することにしました。展開したのは、自動化・効率化を実現するデータ連携ツールと、分析・可視化を可能にするBIツールの2つです。
データ連携ツールについては、実行環境を社内に構築し、誰でも利用できる状態にしました。ノーコードで使えるので、ユーザーは自動化・効率化に関して実現したいことを自力で簡単に実行できます。実行の際には、先ほど話したアクセスコントロールが有効に機能します。データ連携ツールで作成した処理自体は同じでも、実行する社員のロールによって、得られる結果が変わるわけです。
一方、BIツールは、日々の業務で生まれた“ひらめき”や 仮説”を情シスの手を介さずに社員が自ら検証できるという、まさに本プロジェクトの「実現すべき姿」に近づくために欠かせないものです。DDPのもっとも高度な活用法ですが、DWHからデータ連携ツールを使ってデータを集計加工してデータマートに入れ、BIツールで整形済みのデータをアウトプットします。そこまで使いこなせるようになれば、確実に大きなメリットが出てきます。
全社員がそうなればすばらしいですが、なかなかそう簡単にはいきませんよね。
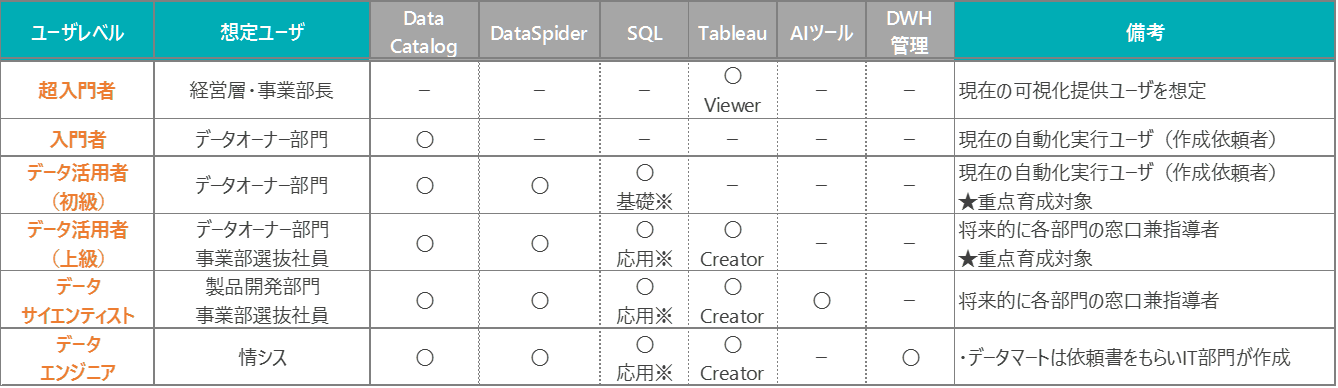
そうですね。よって弊社では、活用・定着フェーズとして、冒頭で軽く触れましたが、DDPを利用する想定ユーザーをデータリテラシーの習熟度別に6階層のペルソナに分類しました。具体的には「超入門者」「入門者」「データ活用者(初級)」「データ活用者(上級)」「データサイエンティスト」「データエンジニア」の6つで、「この人たちはきっとこういうモチベーションでこんな活動をするだろう」という各階層の想定オペレーションを考えました。そして、それぞれの活動のためには、各種ツールの使い方をどの程度理解しておく必要があるか、という知識マトリックスを定義しました。
それによって、各階層に対して必要な教育の内容がある程度明らかになったわけですが、とはいえ一気に全社員を育成することはできません。「実現すべき姿」への最短ルートを検討した結果、弊社ではまず「データ活用者(初級)」「データ活用者(上級)」を重点的に育てることがもっとも効率的だと判断しました。そして、プロジェクト立ち上げ時に想定ユーザーとして選出したメンバー13名を「データ活用力向上育成メンバー」と名づけ、教育の最初のターゲットとしました。
教育対象は決まっても、「なにをどう教えるか」というのは、多くの企業が試行錯誤しているポイントだと思います。
弊社ではまず、どこまでデータ活用できるようになりたいか、という目標を各自に設定してもらいました。その上で、取り組みやすいツールから始め、段階的に難易度を上げていくカリキュラムを組みました。各ツールにもっとも精通している社員が講師となって、各回 1~1.5 時間ほどのセミナーを実施し、その内容を撮影して復習用動画として公開しました。
注意したのは、データ活用力向上育成メンバーの上司や人事に対して、「この教育カリキュラムは正式な業務として実施させてください。業務時間外に取り組んだ場合には、残業として承認してください」とお願いし、メンバーが気兼ねなく勉強できる環境を整えたこと。それと、最後に総合演習課題を課すことを伝え、メンバーに使命感をもってもらえるようにしたことです。
また、脱落者が出ないように、全メンバーの取り組み状況を可視化して、メンバー間の競争意識を醸成しつつ、声かけなどのフォローを徹底しました。それから、エキスパートたちが集まるZoomの“寺子屋”を週1回開催して、気軽に質問できるようにしました。
総合演習課題とはどんな内容ですか?
すべてのツールを活用できないと解けないレベルの内容にしました。業務が忙しいなどの理由で課題を進められないメンバーには、別期間に取り組んでもらうよう案内しました。そして、3か月程度の教育課程を完了した結果、非IT部門の未経験者でも、「4種の神器」を駆使してデータ活用できるスキルレベルに到達することができたのです。総合演習課題についても、コンプリート率は約50%、未達成のメンバーも8割がたできていて、やる気になればできるものだな、と改めて認識しました。
最後のワークショップでは、講師の模範解答のあと、メンバー数名から回答時の思考過程を共有してもらい、皆でモブプログラミングを実施しました。それによって、さまざまなアプローチがあることを共有し、各自に持ち帰ってもらうことができました。
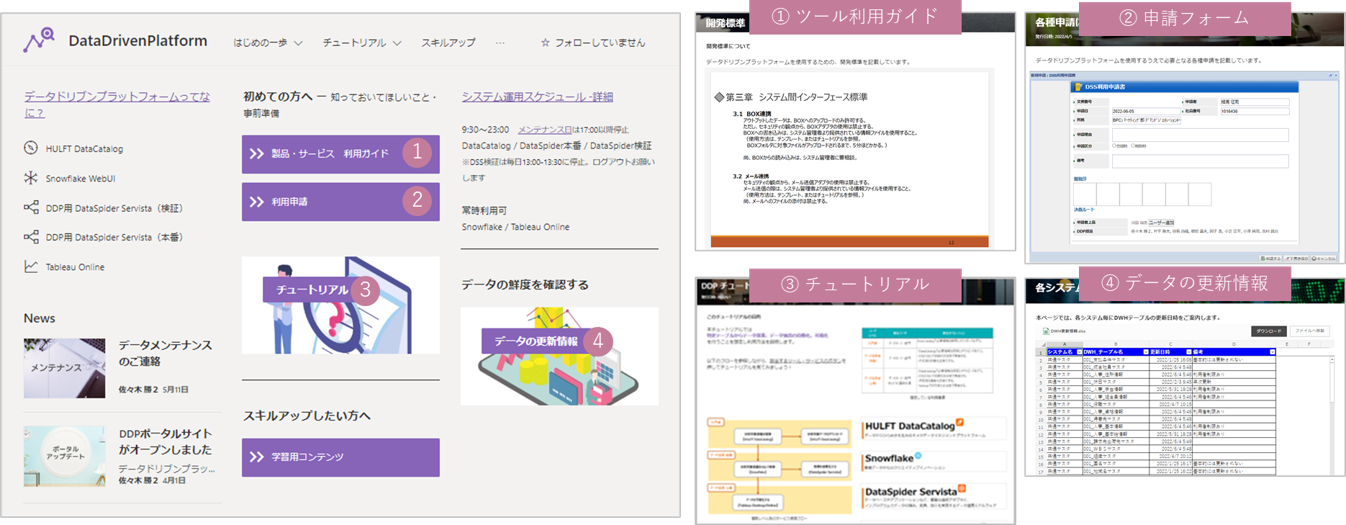
教育期間が終わったあとも、また選抜メンバー以外の人でも勉強できるよう、自主学習やスキル向上をサポートする仕組みを整えました。具体的には、効率的な学習に役立つコンテンツやコミュニケーションチャネルの整備、申請すれば自由に使えるツールの実行環境の提供、DDPに関する全情報を集約したポータルサイトの開設などです。
DDPの利用を定着させ、活性化させるものとして、ほかにどんなことに取り組んでいますか?
1つはオープンコラボレーションです。Slackをはじめ、すべてのコミュニケーションチャネルを全社員に公開して、好事例やナレッジの共有など、コラボレーションを加速させる仕組みを整備しました。
それから、今まさに取り組んでいるのが、「ユーザー同士が称えあい、評価される組織づくり」です。共有された好事例に対してユーザー同士で押す「いいね」を定量化して、評判の高いユーザー、データリテラシー向上に寄与したユーザーにポイントを付与します。そのポイント制度は、人事評価と連動して、社員表彰やインセンティブ支給につながります。そうした改革を続けることによって、弊社は“真のデータエンジニアリングカンパニー”へさらに近づいていけるだろうと考えています。
そうした数々の取り組みは、現時点で具体的にどんな成果を生み出していますか?
2022年4月にDDPの利用を開始したばかりなので、大きな効果を実感できるのはまだ先だと思いますが、すでにたくさんの好事例が出てきています。たとえば、現場部門の担当者が、受注情報シートに請求書送付先などの情報を記入する際、得意先コードを入力するだけで得意先マスタの情報を引き当てて会社名や住所などを自動表示できるようになった結果、入力ミスの防止や入力工数の削減を実現できました。
そうした業務の品質向上や効率化と同じく、ある意味ではそれ以上に重要な成果だと思っているのが、社員の意識や働き方が変わってきたと感じられることです。ITエンジニアが営業と同じデータを見られるようになったことで、自身の開発する製品の意義やお客様のニーズを知ることができるようになったというのは、それを象徴する一例です。
また、業務部門においても、まだデータリテラシーの高い一部の社員の利用が中心ではありますが、そこから好事例が出始めたことで、ITや分析スキルの高くはない社員の間でも「データを使って業務を改善するというのはこういうことなのか」という理解が徐々に広まり、「これまで手作業が当たり前だった業務を効率化できるかも」という発想で考える組織風土が育まれつつあります。
そういう状況を見ると、“ひらめき”や“仮説”を誰でも検証できるという、DDP構築によって目指した「実現すべき姿」に着々と近づいているのだ、と実感します。ただ、弊社はスタートラインに立ったばかりで、本番はこれから。データエンジニアリングカンパニーとして、今回のDDPの取り組みで得た知見を含め、お客様に最適な製品・サービスを提供し、一緒に未来を築いていきたいと心から思っています。
- この事例の記載内容は取材当時のものとなります。本事例の記載内容は予告なく変更することがあります。